如何养龙虾:OpenClaw 技能教程(教、验证、提升)
摘要:「养龙虾」即教 OpenClaw 新技能。本文从技能原理讲起,说明如何教(含自然语言生成技能:跟 OpenClaw 对话让它学习)、如何验证技能质量、以及学成后如何持续提升。以测试工程师视角举例:PRD 拆测试点、接口用例生成、日志分析等。
前置条件:已按 把 Claude/GPT 搬进飞书:OpenClaw 本地部署与接入完整指南 完成 OpenClaw 部署与 API 配置。
速览
| 模块 | 核心内容 |
|---|---|
| 可教哪些技能 | PRD 拆测试点、接口用例生成、日志分析等(测试工程师视角) |
| 怎么教 | 自然语言生成(跟 OpenClaw 对话让它学习)、手写 SKILL.md、引用现成技能 |
| 怎么验证质量 | 看是否被选中、步骤是否执行、输出是否可用 |
| 怎么提升 | 优化 description、细化步骤、迭代测试 |
| 实践成果分享 | 接口清单 → 知识图谱(见第七节) |
一、测试工程师可教龙虾哪些技能?
作为测试工程师,可将 OpenClaw 接入飞书后,教其与日常工作强相关的技能。以下是典型示例。
1.1 PRD 拆测试点
场景:产品发来 PRD 或需求文档,需要快速拆出测试点。
可这样教:当用户说「帮我拆测试点」「根据这个 PRD 写测试点」时,按功能模块拆出:正常流程、边界条件、异常场景、数据验证,输出为 Markdown 列表。
效果:直接贴文档或链接,龙虾即可给出结构化测试点,节省测试设计时间。
1.2 接口用例生成
场景:拿到接口文档,要写接口测试用例。
可这样教:当用户提供接口文档、说「生成接口测试用例」时,按正常请求、参数缺失、类型错误、边界值、鉴权失败等维度生成,每条包含用例名、请求示例、预期结果,输出为 Markdown 表格。
效果:用例结构统一,便于复制到用例管理系统,后续按项目微调即可。
1.3 日志分析
场景:测试或线上出问题,需要快速分析报错日志。
可这样教:当用户粘贴报错日志、说「分析报错原因」时,识别异常类型、分析可能原因、给出排查方向。
效果:直接贴日志即可获得初步分析,适合快速定位问题。
1.4 其他技能
还可教回归测试数据生成(边界值、fuzz 数据),或引用现成技能(如 GitHub 操作)。更复杂的任务如接口清单 → 知识图谱,也可通过教技能实现,文末有实践成果分享。测试工程师可根据项目继续教更多技能,如:用例评审、测试报告总结、缺陷分析等。具体怎么教——包括自然语言生成技能(跟 OpenClaw 对话让它学习)——以及怎么验证、怎么提升,见后文。
二、技能原理:龙虾如何「学」?
理解原理有助于教得更好。
2.1 什么是 Skill?
技能可以将过去分散在提示词、代码片段或零散文档中的隐性知识,显性化、结构化地组织起来,让 AI Agent 按需、稳定地执行专业任务。可将技能类比为新员工的入职材料:把积累的工作经验和最佳实践打包为技能包,让 AI 成为你专业领域的专家。
不同于一次性的提示词(Prompt),技能是可保存、复用、优化的任务解决方案,让 AI 从理解你的指令,变成掌握你的方法。若任务的处理流程相对固定、可稳定重复操作,且需要一致、可靠的输出时,可将其封装为技能。
2.2 技能的本质(OpenClaw)
在 OpenClaw 中,Skill 不是「一段代码」,而是写给 LLM 的说明书。核心文件是 SKILL.md,包含:
- 元数据(YAML frontmatter):技能名称、描述、适用场景
- 指令(Markdown 正文):当用户说什么时,应该做什么、按什么步骤做
LLM 通过阅读这些内容,决定「要不要用这个技能」「怎么用」。所以教龙虾技能 = 写好 SKILL.md。与 Coze 技能 类似,OpenClaw 也采用「渐进式披露」:不会一次性加载技能的全部内容,而是先加载元数据,在对话中判断哪些技能与当前任务相关,再按需加载完整指令,避免上下文窗口过载。
2.3 发现 → 决策 → 执行流程
用户:「帮我根据接口文档生成测试用例」 |
关键点:description 写得好,LLM 才能正确「发现」并选中技能;指令写得清晰,执行才稳定。常见问题是 description 太泛,导致该用的时候没用上。
三、如何教龙虾新技能?
教龙虾技能有三种方式,其中自然语言生成技能是最直观的一种。
3.1 自然语言生成技能:跟 OpenClaw 对话,让它学习
自然语言生成技能是指:在聊天中跟 OpenClaw 对话,用自然语言描述你希望它学会什么技能,OpenClaw 会根据你的描述理解需求、生成 SKILL.md 并写入工作区,从而「学会」该技能。无需手写文件或写代码。
操作步骤:
- 打开 OpenClaw 的聊天窗口(Web 控制台
http://127.0.0.1:18789或飞书) - 用自然语言描述你想要的技能,例如:
帮我创建一个技能:当用户发 PRD 或需求文档、说「帮我拆测试点」时, |
- OpenClaw 会根据你的描述生成
SKILL.md并写入工作区 - 确认生成的内容是否符合预期,必要时在对话中补充或修改
适用场景:快速试新想法、不熟悉 SKILL.md 格式、希望用对话方式「教」龙虾时。与 Coze 自然语言生成技能 思路一致。
3.2 方法二:手写 SKILL.md
若不通过对话,也可直接创建 SKILL.md 文件。指令部分用自然语言写步骤即可,无需写代码逻辑。
示例(接口用例生成技能):
--- |
要点:
- 触发条件:用户可能怎么问,写清楚
- 步骤:按 1、2、3 写,每步可执行、可验证
- 工具:指明用
web_fetch、bash、browser等 - 输出:期望的回复格式、异常时的说法
反例:写「你是一个专业的测试工程师」——这是人设,不是技能指令。
3.3 方法三:引用现成技能,让龙虾「学」
若已有现成技能(如 GitHub 上的用例生成、日志分析、Git 操作等),可直接把链接发给 OpenClaw:
请使用这个技能:https://github.com/openclaw/skills/tree/main/skills/steipete/github |
OpenClaw 会拉取并配置,你无需手写 SKILL.md。适合「站在巨人肩膀上」快速扩展能力。
3.4 自然语言生成技能的流程
若采用跟 OpenClaw 对话的方式教技能,流程如下:
| 步骤 | 动作 |
|---|---|
| 1. 对话描述 | 在聊天中用自然语言说清:什么场景下用、做什么、用什么工具、输出什么样 |
| 2. OpenClaw 生成 | OpenClaw 根据你的描述生成 SKILL.md 并写入工作区 |
| 3. 确认/修改 | 检查生成内容,必要时在对话中补充或让 OpenClaw 修改 |
| 4. 测试 | 用自然语言触发(如「帮我根据这个接口文档生成测试用例」),看是否选中、执行是否正确 |
| 5. 迭代 | 根据反馈在对话中继续调整,或直接修改 SKILL.md(开启 watch 时自动刷新) |
与 Coze 的「描述需求 → AI 编程开发 → 预览测试」思路一致。若想了解 Coze 的技能设计与自然语言生成方式,可参考 Coze 技能概览、Coze 自然语言生成技能、Coze 自然语言搭建教程。
3.5 让龙虾「刷新」技能
创建或修改 SKILL.md 后:
- 若开启了
skills.load.watch: true,网关会自动检测并刷新 - 或对 OpenClaw 说「刷新 skills」、或执行
openclaw gateway restart
四、如何验证技能质量?
教完技能后,需确认龙虾是否「学到位」。与 Coze 技能测试 类似,可从三个维度验证:是否稳定触发、是否稳定执行、输出是否覆盖实际业务场景。
4.1 是否被选中?
现象:发了「帮我拆测试点」,龙虾没用 PRD 拆解技能,而是当普通对话处理。
验证:用自然语言触发,看回复是否符合技能预期。若回复泛泛、没有按技能步骤来,多半是没选中。
排查:检查 description 是否包含用户常说的关键词(如「拆测试点」「接口用例」「日志分析」),是否与其它技能冲突。可在 Web 控制台「技能」页查看当前加载的技能列表。
4.2 步骤是否按预期执行?
现象:选中了技能,但输出缺维度(如接口用例只写了正常流程,没写边界值、鉴权失败)。
验证:对比 SKILL.md 里的步骤,看 LLM 是否执行了每一步。可用同一份文档测多次,看输出是否稳定。
排查:指令是否写得太模糊?把「按维度生成」改成「必须包含:①正常请求 ②必填参数缺失 ③参数类型错误 ④边界值 ⑤鉴权失败」,执行会更稳定。
4.3 输出是否可直接用?
现象:格式乱、难以复制到用例系统,或缺少必要字段。
验证:把输出直接复制到实际工作流(如用例管理系统、测试报告),看是否能用、是否需要大量手工调整。
排查:在指令里明确输出格式,如「输出为 Markdown 表格,列:用例名、请求示例、预期结果」。必要时加示例,让 LLM 有参照。
4.4 验证清单
| 检查项 | 做法 |
|---|---|
| 选中率 | 用 3~5 种不同说法触发,看是否都能选中 |
| 步骤完整性 | 对照 SKILL.md 逐条检查输出 |
| 输出可用性 | 复制到实际工具试用 |
| 稳定性 | 同一输入测 2~3 次,看结果是否一致 |
五、如何让龙虾持续提升?
技能不是一次教完就结束,可根据验证结果不断迭代。以下是常用的提升方法。
5.1 优化 description:提高「被选中」概率
LLM 靠 description 做意图匹配。若技能经常不被调用,多半是描述太泛。应改为:
- 具体:写清「在什么场景下用」,而非「一个有用的工具」
- 含关键词:用户常说的词要出现(如「拆测试点」「接口用例」「日志分析」)
- 区分度:与其它技能的区别要明确,避免多个技能抢同一意图
示例(测试场景):
差:description: 一个测试工具 |
5.2 固化步骤与验收标准
技能的价值在于把隐性流程变成显性指令。若指令写得太模糊(如「按维度生成用例」),LLM 可能漏掉边界值或鉴权失败;改为明确列出 ①正常请求 ②必填参数缺失 ③参数类型错误 ④边界值 ⑤鉴权失败,输出会更稳定。
提升方向:
- 步骤细化:把「执行某操作」拆成 1、2、3 步,每步可验证
- 异常分支:若 API 失败、超时、返回空,应怎么处理
- 输出要求:要求 LLM 以何种格式返回(列表、摘要、表格等)
这样 LLM 不会「自由发挥」,执行更稳定、可复现。
5.3 配置注入:env、apiKey
在 ~/.openclaw/openclaw.json 的 skills.entries 中:
{ |
- 敏感信息放
~/.openclaw/.env,用apiKey: { source: "env", id: "XXX" }引用 - 不同环境(开发/生产)通过
env切换,无需改 SKILL.md
5.4 本地覆盖:在工作区定制
当社区技能「差不多对」但不完全符合你的场景时:
- 在工作区
./skills/创建同名目录 - 复制原技能的 SKILL.md,按你的需求修改指令
- 工作区优先级高于全局,你的版本会覆盖原版
这样既保留原技能更新能力,又能做本地定制。
5.5 迭代测试与观察
建议边改边测:开启 skills.load.watch: true 后,改完 SKILL.md 自动刷新,无需重启。用 openclaw agent --message "用技能做 xxx" 或直接在飞书/Web 聊天中触发,看 LLM 是否选对技能、步骤是否按预期执行、输出是否满足要求,再根据结果调整 description、步骤、异常处理。
六、从安装到提升:一条完整链路
| 阶段 | 动作 |
|---|---|
| 安装 | npx clawhub@latest install <skill> 或手动放到 ~/.openclaw/skills/ |
| 教 | 若有自定义需求,在工作区复制并修改 SKILL.md |
| 配置 | 在 skills.entries 中填 apiKey、env,设 enabled |
| 验证 | 用自然语言触发,看是否被选中、执行是否正确 |
| 提升 | 优化 description、细化步骤、补充异常与输出要求,再测 |
七、我的实践成果:接口清单 → 知识图谱
分享一个我养龙虾的实践成果:发送接口清单文档,让 OpenClaw 帮我输出知识图谱。
我的做法是:在聊天中上传或粘贴接口清单文档,用自然语言说「根据这份接口文档生成知识图谱」。OpenClaw 会解析文档中的接口、模块、依赖关系,输出可交互的知识图谱。
我拿到的图谱包含模块节点(如用户模块、设备模块、数据同步模块等)、API 节点、模块与 API 的包含关系、以及接口间的数据依赖。我可以点击节点查看接口详情(如请求方法、参数、所属模块等),用来快速梳理系统架构、识别依赖链路。
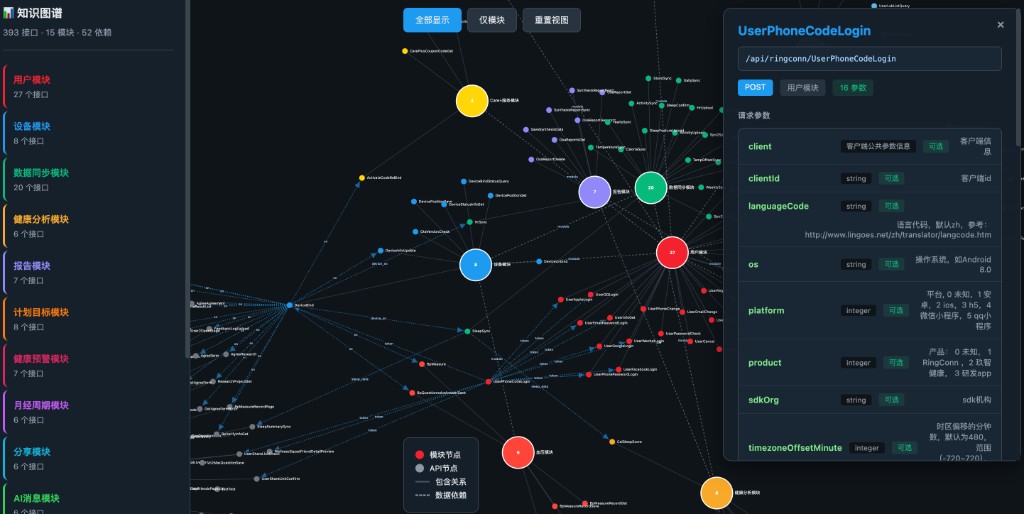
对我而言,接口数量一多,手工梳理模块划分和依赖关系就很耗时且容易遗漏。教龙虾「接口清单 → 知识图谱」技能后,这部分可以自动化完成,测试设计效率提升不少。
📚 延伸资源
本博客相关:
- 飞书多机器人 + 多 Agent:养龙虾进阶 — 多个机器人各司其职
OpenClaw:
Coze 技能(可对比参考):
✍️ 结语
养龙虾的核心是教:通过 SKILL.md 把「做什么、怎么做」写清楚,让 LLM 能发现、决策、执行。理解技能原理有助于教得更好;教完之后,用验证清单确认质量,再通过优化 description、固化步骤、迭代测试持续提升。从教到验证再到提升,形成闭环,即可让龙虾真正参与测试工作。