
🧭 如何把个人博客挂到搜索引擎上?
本文定位说明
这篇文章的目标,是完整回答一个新手最容易卡住的问题:
👉 一个个人博客,从部署完成开始,到最终能在搜索引擎中被搜到,中间到底要做哪些事?
因此本文会按下面的顺序展开:
1️⃣ 先介绍 sitemap、搜索引擎、SEO 等基础名词和角色关系,帮助你建立整体认知
2️⃣ 再按真实顺序,讲清楚 “添加站点 → 验证站点 → 提交 sitemap → 等待抓取” 的完整流程
3️⃣ 最后结合常见使用场景,解释为什么步骤都做了,却可能暂时没有效果
如果你是第一次接触这些概念,建议从头阅读;
如果你已经有博客,只是卡在某一步,也可以按目录直接跳转。
一、先把名词关系讲清楚:这些东西分别是干什么的?
在动手配置之前,先把几个最容易混在一起的名词说明白。
1️⃣ 搜索引擎在整个流程中的作用
搜索引擎(如 Google、Bing)并不是“自动帮你推广网站”的工具,它的核心工作只有三步:
- 抓取(Crawl):访问你的网站 URL
- 解析(Parse):分析页面内容和结构
- 索引(Index):决定是否把页面存进搜索数据库
只有当页面顺利完成这三步,用户才有可能通过搜索关键词找到你的博客。
2️⃣ Sitemap 是什么?
Sitemap(站点地图) 是一个提供给搜索引擎的辅助文件,而不是网站的入口。
它的主要作用是:
告诉搜索引擎:
👉 我这个站点里有哪些页面,我认为它们值得被关注和抓取。
因此,sitemap 更像是:
- 一个 URL 推荐清单
- 一个辅助抓取的信息来源
而不是决定网站是否能被搜索到的唯一因素。
3️⃣ SEO 是什么意思?
SEO(Search Engine Optimization,搜索引擎优化) 指的是:
通过一系列技术和内容层面的优化手段,
让搜索引擎更容易发现你的网站、理解你的内容,并愿意持续收录你的页面。
SEO 不是某一个按钮,也不是一次性配置,而是长期作用在站点层面的整体优化过程。
在本文涉及的内容中,SEO 主要体现在三个方面:
- 可发现性:搜索引擎是否容易找到你的页面(站点结构、链接关系)
- 可理解性:搜索引擎是否能读懂页面在讲什么(内容质量、语义清晰度)
- 可信度:搜索引擎是否愿意持续抓取(站点稳定性、访问表现)
📌 Sitemap 只是 SEO 中的一个辅助工具,而不是决定是否收录的核心条件。
二、整体流程先看一遍:个人博客是如何“接入”搜索引擎的?
从一个刚部署好的博客,到可以被搜索引擎搜到,通常要经历下面这些步骤:
博客部署并可公网访问 |
后面的实操部分,会严格按照这个顺序展开。
三、新手实操:按这个顺序做,最快把“收录链路”跑通 ✅
下面是“最小可行方案”(MVP),先把链路跑通。
Step 0:确认你的页面真的能被访问(很多人第一步就翻车)
打开下面几个地址检查:
- 首页:
https://your-domain.com/ - 任意文章页:
https://your-domain.com/posts/xxx - sitemap:
https://your-domain.com/sitemap.xml(或你实际路径)
你要看到的是:
- 浏览器能正常打开
- 不是 404 / 403 / 5xx
- 如果你有服务器日志或平台监控,确保没有频繁报错
如果文章页本身都打不开,先别谈 SEO。
Step 1:准备一个合格的 Sitemap(最常用:XML)
一个最基础的 sitemap.xml 长这样(示例):
|
关键注意点(真的会影响效果):
- URL 必须是完整绝对路径(别写
/foo.html)(Google for Developers) - sitemap 文件 UTF-8 编码 (Google for Developers)
- 单个 sitemap ≤ 50MB(未压缩)且 URL ≤ 50,000,更大要拆分或用 sitemap index (Google for Developers)
<lastmod>最好真实准确:Google 会在可验证的情况下使用它;乱填可能没收益甚至被忽略 (Google for Developers)<changefreq>和<priority>:Google 明确表示会忽略这两个值(别把精力浪费在“玄学填法”上)(Google for Developers)
✅ 新手建议:先把
loc和靠谱的lastmod做好,就够了。
Step 2:验证你的站点所有权(在搜索引擎中添加你的博客站点)
在添加 sitemap 操作之前,必须先让搜索引擎“认识你的站点”。
你需要先前往各个搜索引擎的“站长平台”注册并添加你的网站地址:
- Google: Google Search Console
- Bing: Bing Webmaster Tools
- 百度: 百度搜索资源平台
下面以 Google Search Console(GSC) 为例说明。
1️⃣ 添加站点(Property)
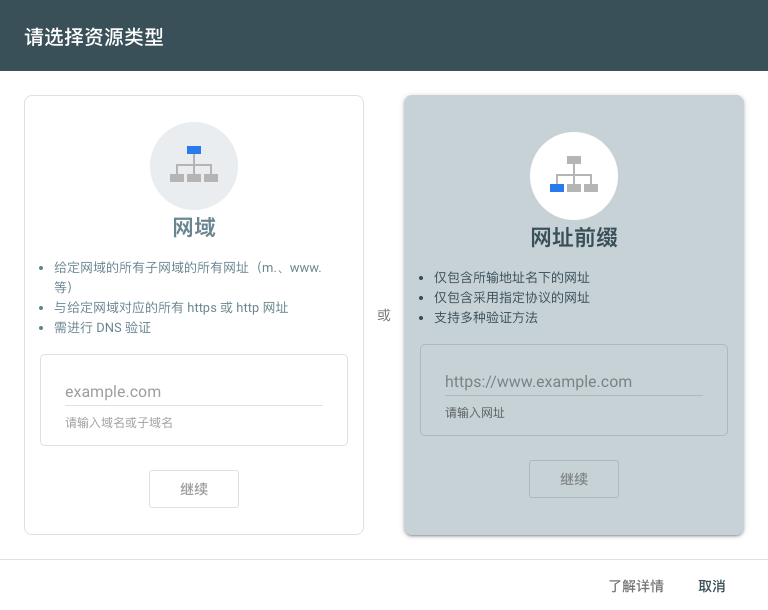
在 GSC 中,点击左上角的属性选择器,选择 “添加资源”。你会看到两种选择:
- 网域属性(Domain):
- 覆盖范围:整个域名下所有的子域名(www, m, blog 等)以及 http/https 协议。
- 验证要求:必须通过 DNS 验证(即去你的域名服务商后台加一条 TXT 记录)。
- 适用人群:拥有独立域名(如
example.com)的博主,这是最推荐的方式。
- 网址前缀属性(URL prefix):
- 覆盖范围:仅限输入的特定 URL 下的页面。
- 验证要求:支持多种方式(HTML 文件上传、Meta 标签、Google Analytics 等)。
- 适用人群:使用 GitHub Pages 子路径(如
username.github.io/blog/)或无法操作 DNS 的用户。
2️⃣ 实操验证步骤(以最常用的两种为例)
方案 A:DNS 验证(对应“网域属性”)
- 在 GSC 输入你的域名(不带 http/https,如
example.com),点击继续。 - 复制弹出框中的 TXT 记录值。
- 登录你的域名服务商(阿里云、腾讯云、Cloudflare 等)。
- 进入 DNS 解析设置,添加一条记录:
- 记录类型:
TXT - 主机记录:
@(或根据要求填空) - 记录值:粘贴刚才复制的内容。
- 记录类型:
- 回到 GSC 点击“验证”。(注:DNS 生效可能需要几分钟到几小时)。
方案 B:HTML 标签验证(对应“网址前缀属性”)
- 在 GSC 输入完整 URL(如
https://example.com/),点击继续。 - 选择“其他验证方法”里的 “HTML 标记”。
- 复制那行
<meta name="google-site-verification" content="..." />。 - Hexo 用户实操:将其粘贴到主题目录下的布局文件(通常是
head.swig或head.ejs)的<head>标签内。 - 重新部署博客后,回到 GSC 点击“验证”。
Step 3:提交 Sitemap 到搜索引擎
验证成功后,即可正式提交 sitemap。Google 官方建议/支持的方式包括:
- 在 Search Console 提交 Sitemap(推荐)
- 在
robots.txt里声明 sitemap 地址
✅ 方式 1:Search Console 提交(推荐)
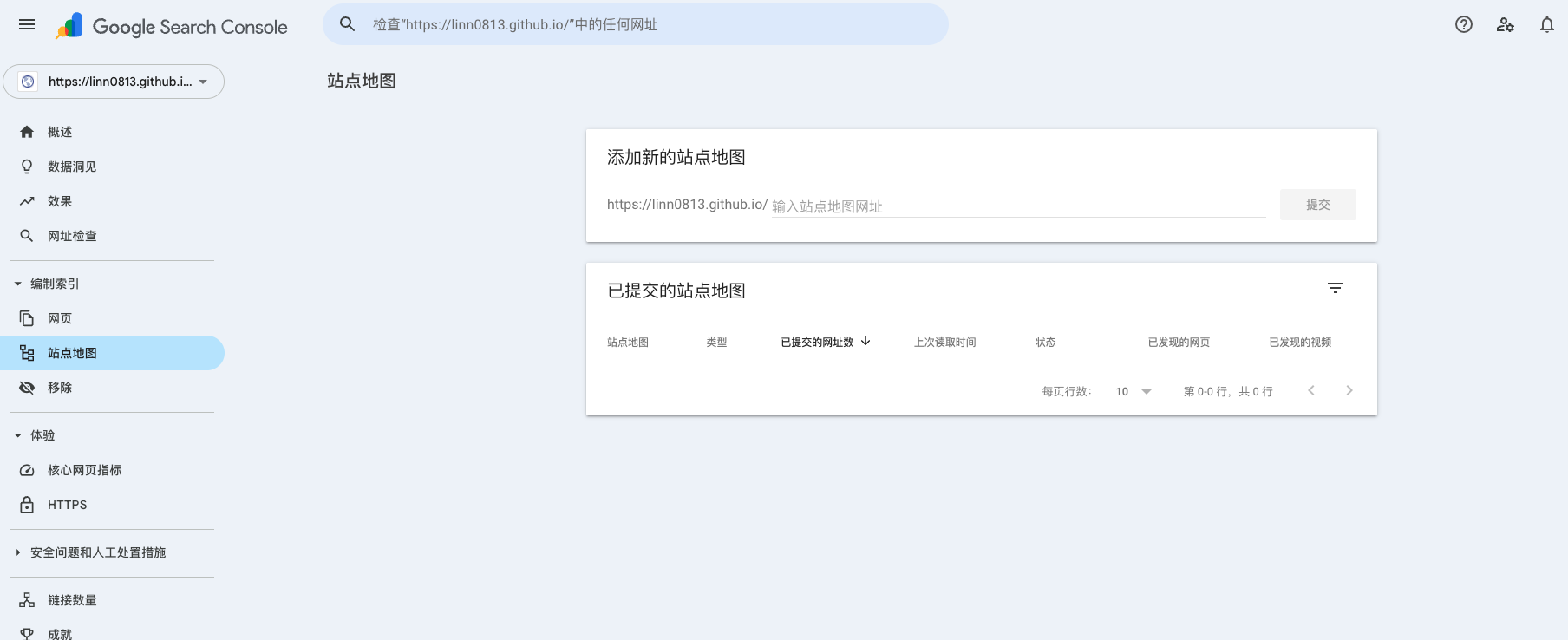
- 在 GSC 左侧菜单找到 “编制索引” > “站点地图”。
- 在“添加新的站点地图”输入框中,输入你的 sitemap 文件名(如
sitemap.xml)。 - 点击“提交”。
- 查看下方的状态列表:
- 成功:Google 已成功读取并开始处理。
- 无法获取/无法读取:通常是 404 或 robots.txt 屏蔽,需按后文 FAQ 排查。
提交之后你能看到 Googlebot 访问 sitemap 的记录以及错误提示,这对排查非常有用。(Google for Developers)
✅ 方式 2:robots.txt 声明(很实用)
在 robots.txt 加一行(任意位置均可):
Sitemap: https://example.com/sitemap.xml |
Google 会在下次抓取 robots.txt 时发现它。(Google for Developers)
四、常见场景问题:为什么步骤都做了,却没效果?
Q1:Search Console 提示“无法获取 / 无法读取站点地图”,最常见原因是什么?
官方社区指南里提到了一类非常常见的情况:
- 你提供的 sitemap 地址是错的 → 404
- 服务器临时不可用/网络错误(可能过一会儿就恢复)(Google帮助)
✅ 你可以先做两步“最小排查”:
- 复制 Search Console 里填写的 sitemap URL,直接在浏览器打开(确认不是 404)
- 用开发者工具/请求工具确认返回码是 200(不要是 30x 循环跳转、403、5xx)
Q2:robots.txt 会不会导致“搜不到”?
会,而且非常常见。
但更常见的是大家用错了 robots 的定位:
- robots.txt 主要用于管理抓取流量,并不等同于“从搜索结果隐藏页面”(Google for Developers)
- 如果你想让页面不出现在搜索结果,应该用
noindex(meta robots 或 X-Robots-Tag),而不是只靠 robots.txt。(Google for Developers)
✅ 快速自检:
- 打开
https://your-domain.com/robots.txt - 看看有没有把文章目录
Disallow了 - 更隐蔽的坑:把 CSS/JS 资源屏蔽了,导致 Google 渲染理解页面困难(Google 也不建议随便屏蔽重要资源)(Google for Developers)
Q3:页面被 noindex 了会怎样?sitemap 会被影响吗?
noindex 的意思是:允许抓取,但不建立索引/不展示在结果里。它可以通过 meta 标签或 HTTP 标头(X-Robots-Tag)设置。(Google for Developers)
另外,有些人会看到“站点地图文件被 noindex 阻止”等提示而慌张——社区指南也提到类似现象需要理解:noindex 不一定阻止 sitemap 被处理,你要结合抓取状态与返回码综合判断。(Google帮助)
✅ 新手建议:
- sitemap 页面本身不需要被索引,关键是 sitemap 里列出的页面不要 noindex(除非你确实不想收录)。
Q4:提交 sitemap 后多久能收录?
没有固定时间。影响因素包括:
- 新站 vs 老站
- 网站可访问性与稳定性
- 站点结构是否清晰(内链)
- 内容质量与重复度
- 抓取频率与资源
你可以把预期设为:
- 新站:几天到几周都正常
- 重要的是:Search Console 能看到抓取与索引的进度,而不是盯着“搜索结果里有没有”。
Q5:为什么“收录了”但“搜不到”?
这通常是排序问题,不是索引问题:
- 你的关键词竞争太强(比如“SEO”这种)
- 内容还不够聚焦(标题/主题不明确)
- 页面权重低(新站、外部引用少)
- 内链结构弱(搜索引擎不认为它重要)
✅ 解决思路:
- 先用更长尾的关键词检索(例如“GitHub Pages sitemap 无法读取”)
- 把文章标题写成用户会搜的句子
- 增加相关文章互链(下一节会讲)
五、进阶优化:当你“能收录”之后,再做这些会非常提效 🚀
下面这些属于“做了就会明显变好”的优化方向。我按收益从高到低排,并补充了可直接落地的实操步骤。
5.1 先看哪里“掉链子”:用 Search Console 诊断全链路
这是最省时间、最不走弯路的一步。
✅ 实操路径:
- 打开 Search Console → “索引 > 页面”
- 看三类数据:已编入索引、未编入索引、已发现 - 目前未编入
- 选一篇“未编入”的页面,点击 “检查 URL”:
- 如果显示 “已抓取但未编入”:通常是内容质量/重复度/内部权重问题
- 如果显示 “已发现但未抓取”:通常是站点稳定性/抓取预算问题
- 对重要页面点 “请求编入索引”,验证是否能被抓取
小结:这一步的意义是 把“没收录”分解成可排查的具体原因,避免盲目折腾。
5.2 站点地图进阶:拆分 + 索引文件(适合文章越来越多的博客)
当你文章量大、分类多,建议使用 sitemap index(站点地图索引文件) 把多个 sitemap 管起来。Google 文档明确提到:站点地图过大需要拆分,并可使用索引文件管理大型站点地图。(Google for Developers)
你可以拆成:
sitemap-posts.xml(文章)sitemap-pages.xml(页面/关于我/导航页)sitemap-tags.xml(标签聚合页)- 然后用
sitemap_index.xml汇总
好处:
- 更好排查:哪个 sitemap 报错一目了然
- 更好管理:更新文章 sitemap 时更聚焦
- 更清晰的站点结构信号
Hexo 实操建议(可选):
- 使用
hexo-generator-sitemap自动生成sitemap.xml - 文章多时用脚本拆分或使用支持 index 的插件
- 同时启用
hexo-generator-feed输出 RSS/Atom,作为辅助发现入口
5.3 把 <lastmod> 做“真实可信”(很多人忽略)
Google 明确说:如果 <lastmod> 始终准确并可验证,Google 会使用它。(Google for Developers)
✅ 实操建议:
- 只有当文章内容“有实质更新”才更新 lastmod(别因为改了个标点就更新)
- 自动化生成 sitemap 时,让它读取文件最后修改时间或构建时间
5.4 内链结构优化:最便宜但最有效的 SEO
新手最容易把博客写成“孤岛文章”:每篇文章只有目录,没有互相链接。
✅ 建议你至少做三种内链:
- 系列导航:
- “上一篇 / 下一篇”
- 相关阅读:
- 文末放 3~5 篇相关链接
- 主题聚合页:
- 把同一主题的文章集中到一个页面(让搜索引擎更容易理解你的主题权重)
实操小模板:
- 每篇文章至少加 2 个“同主题内链”
- 新文章上线后,把它手动加到 旧文章 的推荐列表里(反向内链)
- 主题页标题清晰可检索,例如:
/topics/hexo-seo/
5.5 结构化数据(Schema)与可读性:让搜索引擎更“懂你”
这部分属于高级但很值:
- 给文章页加上 Article/BlogPosting 的结构化数据
- 让标题、作者、发布时间、目录结构更清晰
- 同时也能提升页面在结果中的呈现(视情况而定)
最小可用 JSON-LD 示例:
{ |
实操建议:
- 只要能输出
<script type="application/ld+json">就够用 - 优先确保
headline、datePublished、author、mainEntityOfPage真实准确
5.6 标题与页面结构:把“搜索友好”做到文章里
你可以理解成“内容 SEO 的基础工程”:
标题(Title)优化:
- 把核心关键词放在前 1/3(例如“Hexo sitemap 无法读取怎么解决”)
- 控制在 45~60 个字符内,避免搜索结果被截断
正文结构优化:
- 一篇文章只保留 一个 H1(标题)
- 用 H2/H3 搭结构,保证每节“可扫描”
- 小节标题尽量“可被搜索”的描述句,而不是抽象词
5.7 性能与可用性:别让抓取变成“体验地狱”
你不需要一上来做极致性能,但至少要避免:
- 首屏加载巨慢(图片未压缩、脚本太多)
- 大量 5xx(构建/托管不稳定)
- 频繁 301/302 链式跳转
实操三步走:
- 用 Lighthouse/Pagespeed 跑一次,先看 LCP / CLS / INP
- 图片压缩:文章图尽量控制在 200~500 KB 内
- 静态资源开启缓存(CDN 或托管平台默认缓存)
5.8 robots & noindex 的正确姿势:别混用到自相矛盾
Google 提醒过:混用多种抓取规则与索引规则可能产生冲突。(Google for Developers)
你可以用一个简单原则避免 90% 的坑:
- 想让页面被看到:允许抓取 + 不要 noindex
- 不想让页面被看到:优先 noindex / 认证保护 / 删除页面
- robots.txt:主要用来控制抓取资源与流量,不是“隐藏页面”的万能开关(Google for Developers)




